Fork/Join framework
What’s the fork/join framework
The fork/join framework was designed to recursively split a parallelizable task into smaller tasks and then combine the results of each subtask to produce the overall result.
Basic Components
RecursiveTask
As start section, a ForkJoinPool contain worker threads used to run subtasks. To submit tasks to this pool, you have to create a subclass of RecursiveTask<V> where V is the type of the result produced by the parallelized task (and each of its subtasks) or of RecursiveAction if the task returns no result (it could be updating other nonlocal structures, though).
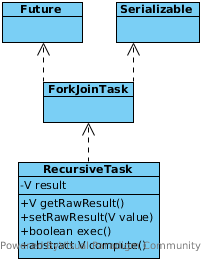
To define RecursiveTasks you need only implement its single abstract method, compute:
protected abstract R compute();
This method defines both the logic of splitting the task at hand into subtasks and the algorithm to produce the result of a single subtask when it’s no longer possible or convenient to further divide it. For this reason an implementation of this method often resembles the following pseudocode:
if (task is small enough or no longer divisible) {
compute task sequentially
} else {
split task in two subtasks
call this method recursively possibly further splitting each subtask
wait for the completion of all subtasks
combine the results of each subtask
}
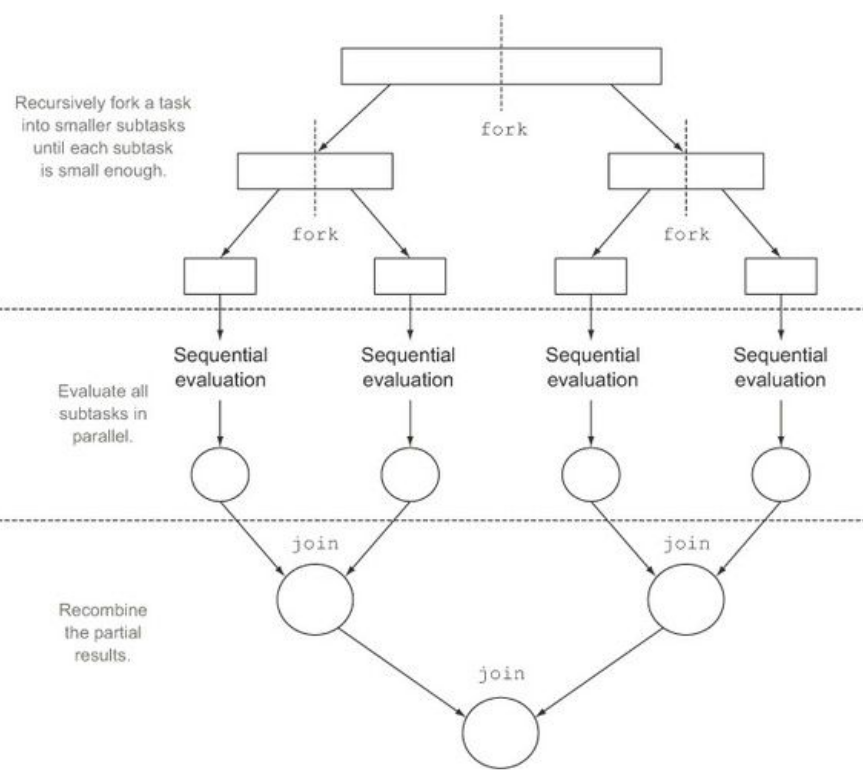
Divide and conquer algorithms
A divide and conquer algorithm works by recursively breaking down a problem into two or more sub-problems of the same or related type, until these become simple enough to be solved directly. The solutions to the sub-problems are then combined to give a solution to the original problem.
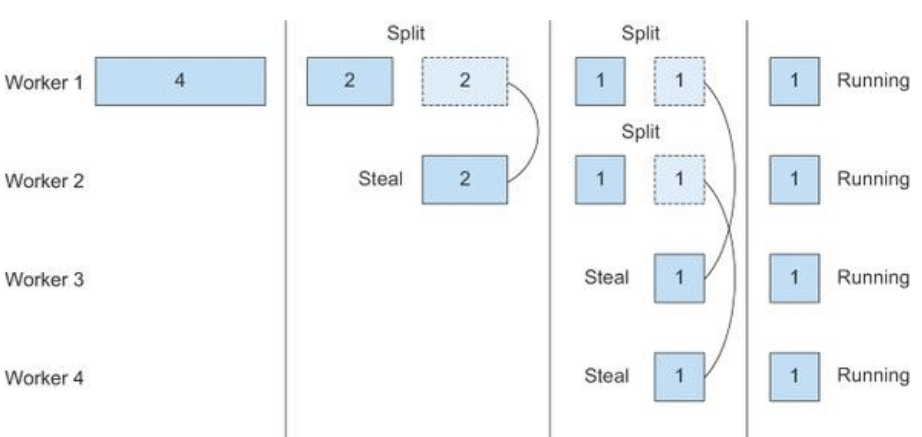
work-stealing algorithm
The work-stealing algorithm is used to redistribute and balance the tasks among the worker threads in the pool.
Best practices for using the fork/join framework
- Invoking the join method on a task blocks the caller until the result produced by that task is ready. For this reason, it’s necessary to call it after the computation of both subtasks has been started. Otherwise, you’ll end up with a slower and more complex version of your original sequential algorithm because every subtask will have to wait for the other one to complete before starting.
- The invoke method of a ForkJoinPool shouldn’t be used from within a RecursiveTask . Instead, you should always call the methods compute or fork directly; only sequential code should use invoke to begin parallel computation.